Simulation of Parallel TCP
1. Introduction
Now, the Internet has more and more high-bandwidth links and cinreasing number of network access technologies. The performance of applications using TCP is significantly lower than the bandwidth available on the network. One reason of poor TCP throughput is high packet loss rate. Packet loss, which indicates network congestion between a sender and receiver, is a broadly problem. When a shared public network becomes congested, packets will be dropped by routers and switches because of queue overflows. This problem determines that parallel TCP connections could be useful more broadly.
Parallel TCP is a TCP enhancement which divides a standard TCP connection into a number of parallel connections. Parallel TCP defeats TCP’s congestion control mechanisms, leading to unfairness and congestion collapse. Parallel TCP flows are robust when systemic and random losses are present. The study showed that the observed loss process limits a single stream to just over 25% of a 100Mb/s link. However, six streams in parallel could obtain more than 80% utilization. Thus, random packet loss could degrade TCP performance, but the parallel TCP has been turn to be significantly better than the single one.
Parallel TCP has many advantages over TCP:
- Faster slow-start
- Can work around OS limitations on max TCP buffer sizes
- Faster recovery
- K-control loops instead of one
- May avoid slow-start burst losses of single giant flow
On the other hand, parallel TCP has some disadvantages as well: - Requires changes to the application to support parallel streams
- If loss is due to congestion, the performance may be worse
- may add to congestion
- It is hard to select the buffer size and number of streams
- May lead to unfairness to other flows
There are some factors that affect aggregate throughput for parallel TCP streams hosts. When an application uses multiple TCP streams between two hosts, the aggregate bandwidth of all s TCP connections can be derived from Mathis equation: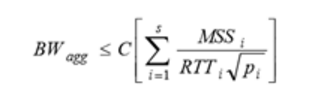
Where MSS is determined on a system wide level by a combination of network architecture and MTU discovery, we could assume that each MSSi is constant for all simultaneous TCP connections. And RTT could be assumed to the same for all TCP connections as well, considering that the entire network path traversed by packets for each TCP connection will likes take the same network path and under the same queuing delays. Thus, the Mathis equation could be rewritten in this way: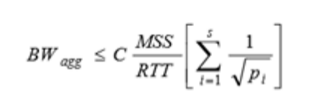
The packet loss rate pi determines the maximum throughput of each stream. It is an important factor in the aggregate throughput of a parallel TCP connection. Each packet loss factor pi should not be affected as long as few packets are queued in routers or switches at each hop between the sender and receiver. This is true until the traffic reaches its capacity. From the equation, the application with s multiple TCP connections should create a large “virtual MSS” on the aggregate connection, which is s times of a single connection. Then, the parallel flow could put more packets during the congestion avoidance algorithm, because a single loss event only causes one of streams to decrease its window size.
We address this topic in our project to implement the parallel TCP in Java and make the transportation over it. In order to have a deep understanding of TCP first, we implement the TCP/UDP, and finish the tests to compare them in speed and reliability. Then based on regular TCP, we further design and add new mechanism to the protocol, and come up the Parallel TCP. With the new protocol, we transport files over local server, and compare the results from local area network. Related work and our experiments are introduced in the following sections.
2. Methodology for Parallel TCP
Our goal is to build a parallel TCP to realize fast transportation. First, we have a target file which is about to sent from server to client. For single TCP, we have no necessity to do any pre-processing since it only have one transportation route. Now in parallel TCP, we have to split this find into several sub parts. Typically, there are two ways to split file. The first is to split the file into several big chunks, with the exact number of TCP sub paths. When transporting data, each chunk will be split into packets for further allocation. The system will assign the packets to each corresponding TCP route. When one TCP finishes the current transportation, allocate another packet to it. The other splitting criteria is to directly cut the file into multiple small packets.The number of packets is several times larger that the number of TCP subflows. The system just sequentially sends each file to each TCP route. In this project, we implement the first strategy to realize file splitting.
In this project, we not only aim at using several TCP paths to transport data from server to client, but also tend to change the number of sub-paths and measure the performance via calculating the throughput. Therefore, we increase the number of subflows from 1 to 10. Then we calculate how much time is taken for transporting a file.
For single TCP, we measure its throughput by: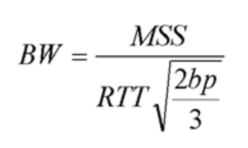
For parallel TCP throughput model, we measure the total bandwidth by: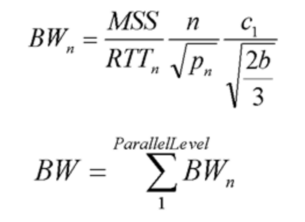
3. Implementation
3.1 Implement TCP/UDP Protocol
The stack structure of TCP/UDP is shown in the figures below. We can tell from them that UDP lacks of packet sequence number and the ACK from receiving host. It means the UDP usually uses less RAM space and is faster than TCP. On the other head, UDP can’t deal with the loss packet problem and also have no congestion control so that the accuracy of transportation relies on the scale of file we transported. Basically, UDP doesn’t connect the receiver and sender before transportation, which is different from the TCP three-way handshake.
That is, UDP is a fast, comfortable, non-connection and unreliable form of data transportation.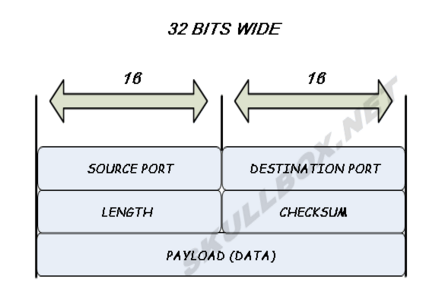
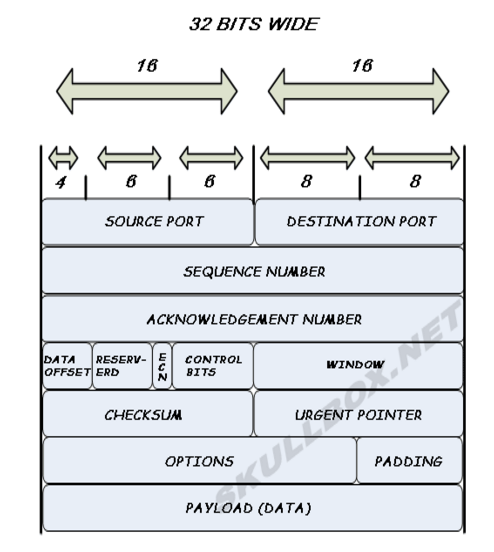
To implement the project, we search for the original code for these different protocols and try them respectively on video file transportation. The video we selected to transport is around 2 GB which is large enough to compare the transportation time over different protocols. To test the original code with certain video file, first is to create a receiver with specific IP address and port for the sender to transport to.
The protocol can be defined either “udp” or “tcp” as which your protocol you choose. The port number is set for the sender to listen to. After open then receiving host, we can transport the video file from a sender.
Same with receiving host, the protocol and port parameter in sender defines type of protocol you choose and the listening port from receiver. Meanwhile, the host is the ip address of the file sender (will be 127.0.0.1 if test on the same computer). And the filename is the certain file for test.
3.2 Image Transportation
First we test the two protocols on a jpg file, the size is 364KB. When doing tcp, we can receive an exact image file with the similar size.
While doing udp, the transportation will stop the first time the receiving host loss a packet and meets flow streaming congestion as the figure below indicates. In a certain test, the receiver exactly receives almost all the packet but not stop since meeting a deadlock. However, in most case, the transportation will congest at one point and begin the dead loop.
To compare the performance, we can compare two images directly. We can tell that the transportation through tcp receive and revert to the original image perfectly while the udp one, because of the non-sequence and no congestion control, shows a bad one.

3.3 Implementation of Parallel TCP Transportation
With the implemented TCP/UDP, we compare the performance of the parallel TCP with regular TCP. Specifically, we designed a multi-threads program with each thread performs as a single port of the parallel TCP. The strategy is that, to speed up the transportation between server and client, one can use parallel TCP over regular TCP because parallel TCP can make full use of the bandwidth, slow-start faster and recover faster.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33try
{theAddress = InetAddress.getByName(args[1]);}
catch(UnknownHostException e)
{printError("The specified host could not be found on the network");}
theFile = new File(args[2]);
if(!theFile.canRead()) printError("There was an error opening the specified file");
// Create the sender object
long length = theFile.length();
long currentSize = 0;
long packet = length / 8192;
if (length%8192 != 0)
packet++;
long packetPerTCP = packet / portNumber;
if (packet%portNumber != 0)
packetPerTCP++;
long piecesSize = packetPerTCP * 8192;
long Pointer = 0L;
TCPSender sh = new TCPSender(theAddress, 8080, theFile, 0L, 0L);
sh.shakehand();
Thread t = null;
for (int i=0; i<portNumber; i++) {
if (i == portNumber-1)
t = new Thread(new TCPSender(theAddress, thePorts[i], theFile, Pointer, length-Pointer));
else
t = new Thread(new TCPSender(theAddress, thePorts[i], theFile, Pointer, piecesSize));
Pointer += piecesSize;
t.start();
To implement the parallel TCP, we use the multi-thread programming to open parallel ports for the same IP. The code above shows to open the multi-thread in server.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33for (int i=0; i<portNumber; i++) {
thePorts[i] = 8081+i;
buffer.add(ByteBuffer.allocate((int)(filesize/portNumber+8192)));
}
Thread t = null;
for (int i=0; i<portNumber; i++) {
t = new Thread(new TCPReceiver(thePorts[i], buffer.get(i)));
t.start();
ls.add(t);
start = System.nanoTime();
}
try {
for(Thread thread : ls)
thread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
FileOutputStream out = new FileOutputStream(filename);
byte[] bt = new byte[8192];
for (ByteBuffer b : buffer) {
b.flip();
while (b.position()<b.limit()) {
b.get(bt, 0, (b.limit()-b.position()) < bt.length ? (b.limit()-b.position()) : bt.length);
out.write(bt);
}
System.out.println("Thread done!");
}
out.close();
long end = System.nanoTime();
System.out.println((double)(start-end)/(long)1000000000);
The code above shows the client receiving files from different ports and reconstruct it from buffer to disk. And for the opening of exact ports we chosen, first is to send the file information including file name and file size through the first TCP transportation. Then we cut the original file into pieces and each piece be transported through one port with a token to record its indices with which the client can rearrange the packets in buffer to guarantee the reception of file without error.
There are many different ways to arrange the transportation such as arrangement of packets one by one or send the file block by block through certain parallel TCP. The performance of the different arrangement could be different slightly, because the rearrangement for clients would be much easier with the block by block strategy over packet by packet. On the other hand, the first strategy will save some time for the cut of blocks.
In the experiment, we choose the second dividing strategy for its easy implementation and we test the performance of the same file transportation between different ports in local server and the transportation of file in local area network.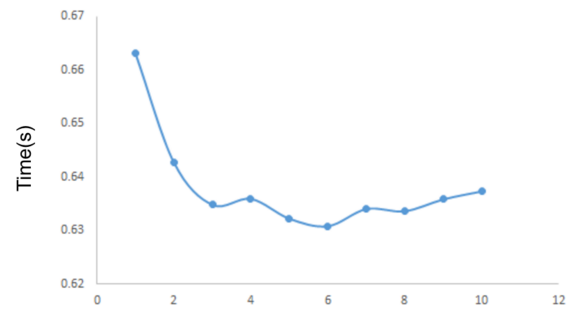
The graph shows the performance for different number of ports we selected. It shows the transportation time of a 55 MB file over number of parallel TCP on local server. the throughput changes rapidly when the port number increases at first. And after the ports increases to 6 and 7, the transportation time becomes stable with going a little higher which is because of more congestions in parallel TCPs.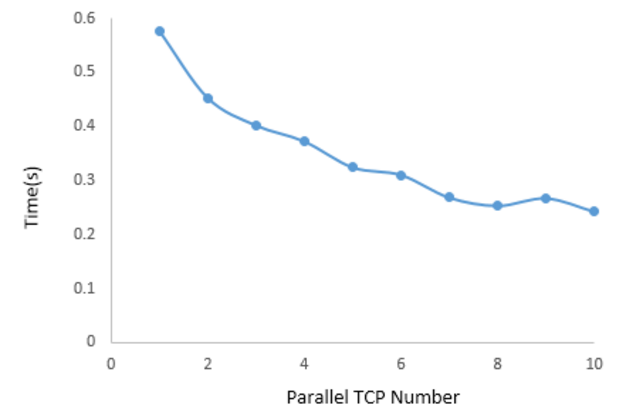
The above graph shows the transportation through local area network. The improvement of multi-thread is smaller while stable comparing with transportation on the local server. This is mainly because the network flow is restricted by the bandwidth while the transportation in local server benefits from the faster reading and writing from the disk. Another difference is founded when number of ports increases to 6. There is a bad record there showing an anti-trend of change on throughput. This happens randomly when the transportation meets more congestion in local network. Due to a worse fast recovery mechanism over single TCP, the parallel TCP need more time to deal with a resend of lost packet.
5. Conclusion
In the project, we learn the parallel TCP from literature and implement one by ourselves. From the results, we can find that the parallel TCP improves the throughput and transport files faster than the regular TCP. It can make full use of the bandwidth to transport messages even there is packets loss. If one thread experiences the packet loss, the others will still work efficiently. Although the speed is improved, the change is not significant, because the parallel TCP implemented by ourselves is not perfect. It is actually simplified for the project. If we have a parallel TCP with complete congestion control and recovery mechanism. Parallel TCP is expected to have better performance.